Redis에서 조회수 증가 동시성 이슈
조회수를 Redis에 캐싱하고 나중에 RDB로 write back해야하는 일이 있었다.
Redis에서 해야하는 일은 게시물이 조회되면 → 해당 게시물의 id를 key로하여 조회수를 저장하는 일이다.
이슈 사항
먼저 조회수에 대한 상세 로직은 아래와 같다.
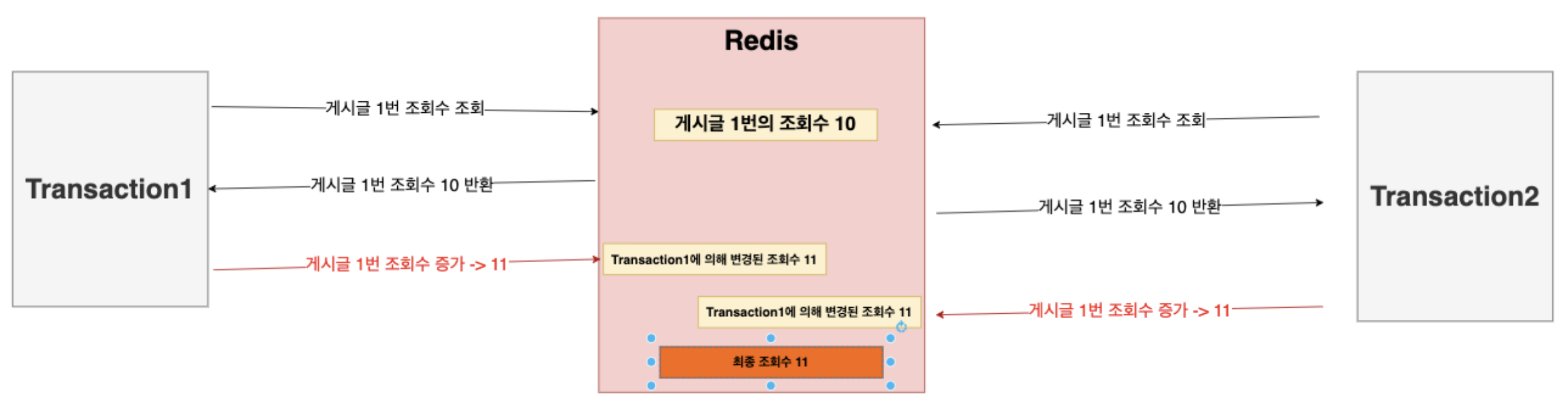
- Transaction1(T1)이 게시글 1번의 조회수를 조회한다.
- T1은 조회수를 1 증가한다.
- 조회수는 최종적으로 1증가 되어 Redis에 저장된다.
하지만 T2가 동시에 요청을 하면?
아래와 그림과 같은 이슈가 발생한다.
T1과 T2가 조회수를 조회한 후 T1이 변경하고 T2가 변경했을 때 각자 조회한 조회수가 동일했기 때문에 동기화가 안되는 현상이다.
즉, 최종적으로는 조회수가 12가 되어야 하는 것이다.
이슈가 있던 코드를 살펴보자.
increaseHits()를 보면, getHits()를 하고, RedisHits라는 객체에서 increase()에게 요청을 하여 조회수를 증가시킨다.
이후 put()을 하게된다. 이 코드의 문제는 getHits에서 Redis 데이터를 조회하고 그 찰나에 T2가 조회 요청을 했기 때문이다.
테스트를 해보면 랜덤하게 몇백개의 조회수만 증가했다. 조회수가 10_000이 되었어야 헀는데 실패했다.
그러면 어떻게 해결해야 할까?
해결 방법
고려했던 방법
Spring Data Redis가 제공하는RedisTemplate의increment()메서드increment() 메서드는 key에 대한 value를 증가시켜주는 메서드이다.트랜잭션(multi)을 사용하여 watch 활용.
트랜잭션을 사용하는 방법에는 Spring Data Redis에서 2가지 방법이 있다.SessionCallback Interface
- Redis 명령어를 직접 인터페이스를 통해 사용해서 조작하는 방법
- 직접 명령어를 제어해보려고 했으나, Redis의 트랜잭션은 lock을 사용하지 않고,
discard를 하게되어, 이후 트랜잭션은 제거해버림.
이후 트랜잭션의 조회수 증가가 제거되는 것이 아닌 대기 후 변경된 조회수를 동기화하여 update해야하는 것이기 때문에
맞지 않았음.
@Transactional 사용
- 사용해봤는데 실패헀음.
increment() 사용하기
개선한 코드를 보면 아래와 같다.getHits()를 사용하지 않고, RedisTemplate이 제공하는 increment()를 사용했다.
increment()의 내부를 살짝 살펴보자.
DefaultHashOperations.java
해당 클래스에서 execute()를 실행하는데 RedisCallback을 사용하고 있다.RedisCallback은 Redis를 직접 사용할 수 있는 인터페이스이다. Spring Data Redis가 구현체를 제공하고 있다.
LettuceHashCommands.java
hIncrBy()를 살펴보면, just()를 실행하고 있다.
LettuceInvoker.java
just()를 보면, synchronizer로 invoke()를 하고있다.
즉, 동기처리로 처리를 하는 것 같다.
Redis에서 데이터 삭제 시 동시성 이슈
Redis에서 조회수를 MySQL인 RDB로 특정 시간마다 반영해야 하는 기능 중 발생한 이슈이다.
MySQL을 RDB라고 하고, Redis는 Redis로 칭하겠다.
이슈 사항
먼저 기능에 대한 상세 로직을 보자.
- Redis에 조회수가 담겨있다.
- 특정 시간마다 RDB로 반영하고 캐시는 삭제한다.
아주 간단한 로직이다.
RDB에 반영 도중 조회수 증가 요청이 온다면?
요청 수만큼 조회수는 누락된다.
기존에 작성한 로직을 그림으로 살펴보자.
- 스케줄러 트랜잭션(T1)이 Redis에 포스트 1번의 조회수를 조회 요청한다.
- 다른 스레드(T2)는 조회수 증가를 요청한다.
- T2에 의해 Redis에 조회수는 11이 된다.
- 하지만 T1의 조회수는 이미 10으로 조회가 되었다.
(T3..... T10까지 만약 요청이 들어왔다면, 그만큼 차이가 나게된다.) - RDB에 조회수 10 반영
- Redis flushAll하여 초기화
delete로 단건으로 삭제해도 다를게 없음. 어차피 그 사이에 조회수 증가 요청이 오는 것이기 때문이다.
이슈 코드
원활한 테스트를 위해 RDB에 반영 전에 1초 지연을 했다.
조회수 증가 동시성 이슈 코드와는 다르게 hash가 아닌 string을 사용하고 있는데 이슈 해결을 위해 변경한 것이다.
이후 알아보자.updateRDB()를 보면된다.
테스트
테스트 코드로 작성이 불가능하여 실제 요청으로 테스트를 진행했다.
→ 방법을 알아냈는데 살짝 트레이드오프가 있다. 마지막에 알아보자.
불가능한 이유는 1초 대기하는 중에 조회수 증가 요청을 해야하는데 그 방법을 찾지 못했다.
1초 대기를 하는 이유는 단순히 편하게 테스트하기 위해서이다. 딜레이없이 그냥 막 요청을 눌러도 된다.
테스트를 진행 해보자.
1번 포스트로 테스트를 진행했고, hits인 조회수는 0인 상태이다.

포스트 조회를 하면 조회수 증가가 되어 Redis에 저장되고, 스케줄러가 실행되어 updateRDB()가 실행되어
RDB에 반영이 된다. 쿼리 로그는 일부러 보이지 않게 제거했다.- incrementHits: incrementHits()가 실행되어 증가된 값이다.
- hasNext() 진입: updateRDB()가 실행되어 Redis에서 key를 찾은 상태이다.
- updateRDB getHits(), 1초대 대기: updateRDB()가 실행되어 Redis에서 조회한 조회수이다.

RDB에 반영이 되었다.

중요!!! updateRDB() → hasNext() → Redis에서 조회수 조회 후 1초 대기 →
incrementHits()→ 대기 끝(RDB 반영)
이번에 테스트할 것은 위의 그림과 같이Redis에서 조회수 조회 후 바로 incrementHits()인 조회수 증가 요청이 올 때를 테스트하는 것이다.
조회수 증가 요청은 총 5번을 하였다.
회색 박스를 보면, 사이에incrementHits = 4가 1개 있다. 이건 누락되는 데이터가 된다.update RDB getHits(), 1초 대기 = 3의조회수가 3이기 때문이다.
이후 flushAll()을 해서 캐시를 초기화하기 때문이다.
RDB 결과를 보면 6이 아닌 1개가 누락된 5인 것을 확인할 수 있다.

해결 방법
Redis 자료구조인 string의 getdel을 사용한다.
선택한 이유
- 기존에는 hash가 성능이 좋아서 선택했지만, 테스트 결과 미묘하다.
정말 트래픽이 많이 않다면, 의미가 있을까? 일단 트래픽이 그렇게 많지 않은 서비스라고 가정함. - hash에도 hdel이 있지만, 삭제한 값을 반환하지 않는다.
우리는 삭제한 조회수를 RDB에 update해야하기 때문에 필요하다. - string은 getdel을 사용하면, 삭제한 값을 반환한다.
getdel() 사용하기
getdel을 사용하여 동시성 문제를 개선해보자.
변경된 코드만 첨부.
- getAndDelete(): Redis의 getdel명령어를 제공하는 RedisTemplate 메서드
- getAndDel(): flushAll()을 없애고, getdel()로 대체
테스트
조회수 1인 상태에서 시작

조회수 증가 요청을 6번한다.
회색 박스를 보면, 대기 중 증가 요청이 1개 들어온걸 확인할 수 있다.
동시성 이슈가 개선되었다면, RDB에는 7개로 변경이 돼야한다.
RDB 확인

테스트 코드로 동시성 테스트하기
처음에는 방법을 못찾았는데 트레이드오프를 하기로 했다.
테스트 코드에 딜레이를 주는 것이다. 장단점을 알아보자.
장점
- 테스트 자동화가 된다.
단점
- 테스트 코드에 딜레이가 들어가므로 딜레이 시간에 의존적이다.
만약, 로직 속도가 느려지거나 빨라지면, 영향을 받게되어, 꺠지기 쉬윈 테스트가 된다. - 즉, 추측성 테스트일 수 있다.
단점이 있음에도 선택한 이유
- 결국 API 요청 테스트를 해야하긴 하지만, 수정사항이 생겼을 경우 매번하기 번거롭다.
- 만약 로직 속도가 느려지거나 빨리져서 테스트가 깨지면, 그 때 다시 수정해도 크게 리소스가 들 것 같지는 않다.
예상하는 이슈
문제를 해결하며, 로직이 미세하게 변경된 부분이 있다.
변경 전에는 RDB에 update를 하고, Redis 캐시를 delete를 했다.
변경 후에는 Redis 캐시를 delete하고, RDB에 반영했다.즉, RDB에 반영이 실패해도 Redis 캐시는 삭제된 것이다.
이런 부분은 Replica를 만들어서 해야하는 건가?
알게된 것
- Redis는 싱글 스레드이다.
- 하지만 완전한 싱글 스레드는 아니고 역할 별로 스레드가 몇개 존재하는 것 같다.
- Redis는 싱글 스레드라서 Atomic을 보장하는데, 제공하는 명령어를 사용해야 한다.
이런 동시성 이슈가 발생한 이유가 명령어를 분리해서 조회따로 변경따로 했기 때문에
그 사이에 다른 요청이 들어왔기 때문이다. 즉, 이상하게 코딩하면, 보장받지 못한다. - 싱글 스레드이기 때문에 특히 O(N)을 지양하고, O(1)을 지향해야 한다.
'Spring' 카테고리의 다른 글
| SpringBoot Request 받는 여러가지 방법 (2) | 2022.12.04 |
|---|---|
| @JsonFromat, @DateTimeForamt이 계속 헷갈린다! (0) | 2022.11.19 |
| 스프링 부트 Logger 사용법 및 팁 (0) | 2022.05.11 |
| 스프링 순환 참조와 생성자 주입을 사용해야 하는 이유 (0) | 2022.04.20 |
| JPA Auditing으로 생성시간, 수정시간 자동화하기 (0) | 2022.04.19 |